Table of Contents
Introduction to Overfitting and Underfitting
When building machine learning models, two of the most critical challenges that data scientists face are overfitting and underfitting. These concepts are crucial to understand because they directly impact the performance and accuracy of your models. In this blog post, we’ll dive deep into what overfitting and underfitting are, how they occur, and how you can prevent them to build more reliable and accurate models.
What is Overfitting?
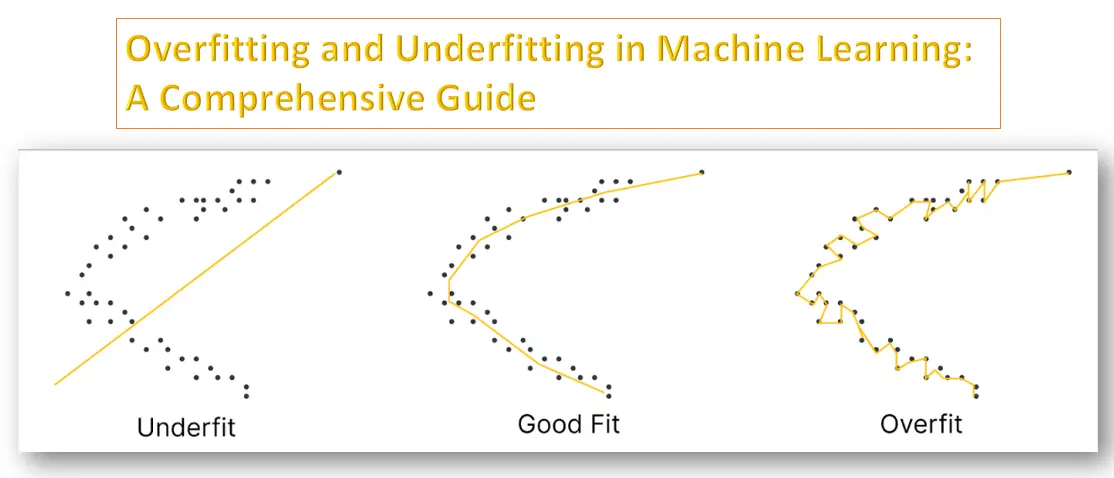
Overfitting occurs when a machine learning model captures not only the underlying pattern of the data but also the noise. This happens when the model is too complex, having too many parameters relative to the number of observations. As a result, the model performs exceptionally well on the training data but fails to generalize to unseen data.
When a model performs very well for training data but has poor performance with test data (new data), it is known as overfitting. In this case, the machine learning model learns the details and noise in the training data such that it negatively affects the performance of the model on test data. Overfitting can happen due to low bias and high variance.
Example of Overfitting
Imagine you’re training a model to predict housing prices. If your model is too complex—say it has many layers and a high number of neurons—it might start learning the “noise” in your training dataset. This could be small fluctuations in the data that aren’t relevant to the overall trend. When you test the model on new data, it doesn’t perform well because it was too “tuned” to the specifics of the training data.

What is Underfitting?
Underfitting, on the other hand, occurs when a machine learning model is too simple to capture the underlying pattern in the data. This happens when the model doesn’t have enough parameters or complexity to learn from the data, leading to poor performance on both the training and test datasets.
Example of Underfitting
Continuing with our housing price prediction example, if your model is too simple—like using a straight line to fit data that requires a more complex curve—it won’t capture the intricacies of the data. As a result, the model will perform poorly on both the training and new data.

Difference between overfitting and underfitting in machine learning
Overfitting and underfitting are two ends of the spectrum in model performance, each presenting distinct challenges.
Overfitting occurs when a model learns not only the underlying patterns in the training data but also the noise and random fluctuations. This leads to a model that performs exceptionally well on the training data but poorly on unseen or test data. In contrast, underfitting happens when a model is too simple to capture the underlying trends in the data. As a result, it fails to perform well on both training and test datasets.
Compare Overfitting and Underfitting
Here’s a detailed look at the differences between overfitting and underfitting:
| Overfitting | Underfitting | |
|---|---|---|
| Definition | The model learns the details and noise in the training data to the extent that it negatively impacts its performance on new data. It fits the training data too closely and captures noise as if it were a pattern. | The model is too simplistic and fails to capture the underlying patterns of the data, leading to poor performance on both training and unseen data. |
| Model Complexity | Typically occurs when a model is too complex with many parameters or features relative to the amount of training data. This includes overly deep neural networks or highly flexible algorithms. | Happens when a model is too simple, such as a linear model for a problem that requires a more complex relationship, or if it has too few parameters to capture the underlying data patterns. |
| Training vs. Testing Performance | Shows very high accuracy on training data but significantly lower accuracy on test data or validation data. The model is excellent at memorizing training examples but struggles with generalization. | Exhibits poor accuracy on both training and test data. The model does not perform well even on the data it has seen during training, indicating it has not learned enough. |
| Symptoms | High variance: Model predictions fluctuate significantly with different subsets of training data. Complex decision boundaries: In classification tasks, the decision boundary is highly irregular and overly fitted to the training data. | High bias: Model predictions are consistently off regardless of the training data used. Simple decision boundaries: In classification tasks, the decision boundary is too simplistic and does not capture the data's complexity. |
| Techniques for Mitigation | Regularization: Apply techniques such as L1 or L2 regularization to penalize complex models. Cross-validation: Use k-fold cross-validation to ensure the model generalizes well across different subsets of the data. Pruning: Reduce the complexity of the model by removing nodes or features that contribute little to the model’s performance. Early Stopping: Monitor the model’s performance on a validation set and stop training when performance degrades. | Model Complexity: Increase the complexity of the model, such as using a more complex algorithm or adding more features. Feature Engineering: Add more relevant features or use polynomial features to capture complex relationships. Hyperparameter Tuning: Adjust the model’s hyperparameters to improve its performance and capacity. |
How to Detect Overfitting and Underfitting
Detecting whether your model is overfitting or underfitting involves comparing its performance on the training data with its performance on unseen (validation or test) data.
- Overfitting: If your model performs significantly better on the training data than on the validation data, it is likely overfitting
- Underfitting: If your model performs poorly on both the training and validation data, it is likely underfitting.
Techniques to Avoid Overfitting
- Cross-Validation:
- Use techniques like k-fold cross-validation to ensure that your model performs well on different subsets of your data. This helps in verifying that the model generalizes well.
- Simplify the Model:
- Reduce the complexity of the model by decreasing the number of features, parameters, or layers. Regularization techniques like L1 and L2 can also help in simplifying the model.
- Pruning:
- In decision trees, pruning helps by removing branches that have little importance and are likely to cause overfitting.
- Early Stopping:
- Monitor the performance of the model during training, and stop training when the performance on the validation set starts to degrade.
- Data Augmentation:
- Increase the size of your training data by augmenting it, which can help the model to generalize better.
Techniques to Avoid Underfitting
- Increase Model Complexity:
- Add more layers or parameters to your model to make it more capable of capturing the underlying patterns in the data.
- Feature Engineering:
- Create new features that can help the model understand the data better.
- Longer Training Time:
- Sometimes, underfitting can occur because the model hasn’t been trained long enough. Increasing the number of epochs can help.
- Hyperparameter Tuning:
- Adjust the hyperparameters like learning rate, batch size, and number of epochs to find the best configuration for your model.
Balancing Between Overfitting and Underfitting
Achieving a balance between overfitting and underfitting is the key to building a robust machine learning model. You want your model to be complex enough to learn the underlying patterns but simple enough to generalize well to new data.
Conclusion
Understanding overfitting and underfitting is essential for anyone involved in building machine learning models. By recognizing the signs of these issues and implementing the techniques discussed, you can build models that not only perform well on your training data but also generalize effectively to unseen data.
Further Reading
For those interested in diving deeper into this topic, here are some excellent resources:
Easy to understand